.png)

How To Set the Right Apache Kafka Batch Size
Setting the right Kafka batch size is critical for improved efficiency. It directly affects throughput, latency, and cost—especially in managed platforms like Confluent Cloud. Yet many engineering teams don’t have the time or visibility to fine-tune it properly.
Let’s break down why batch size matters, what makes it tricky to optimize, and how to set Kafka batch size safely and intelligently.
What Is Kafka Batch Size and Why Does It Matter?
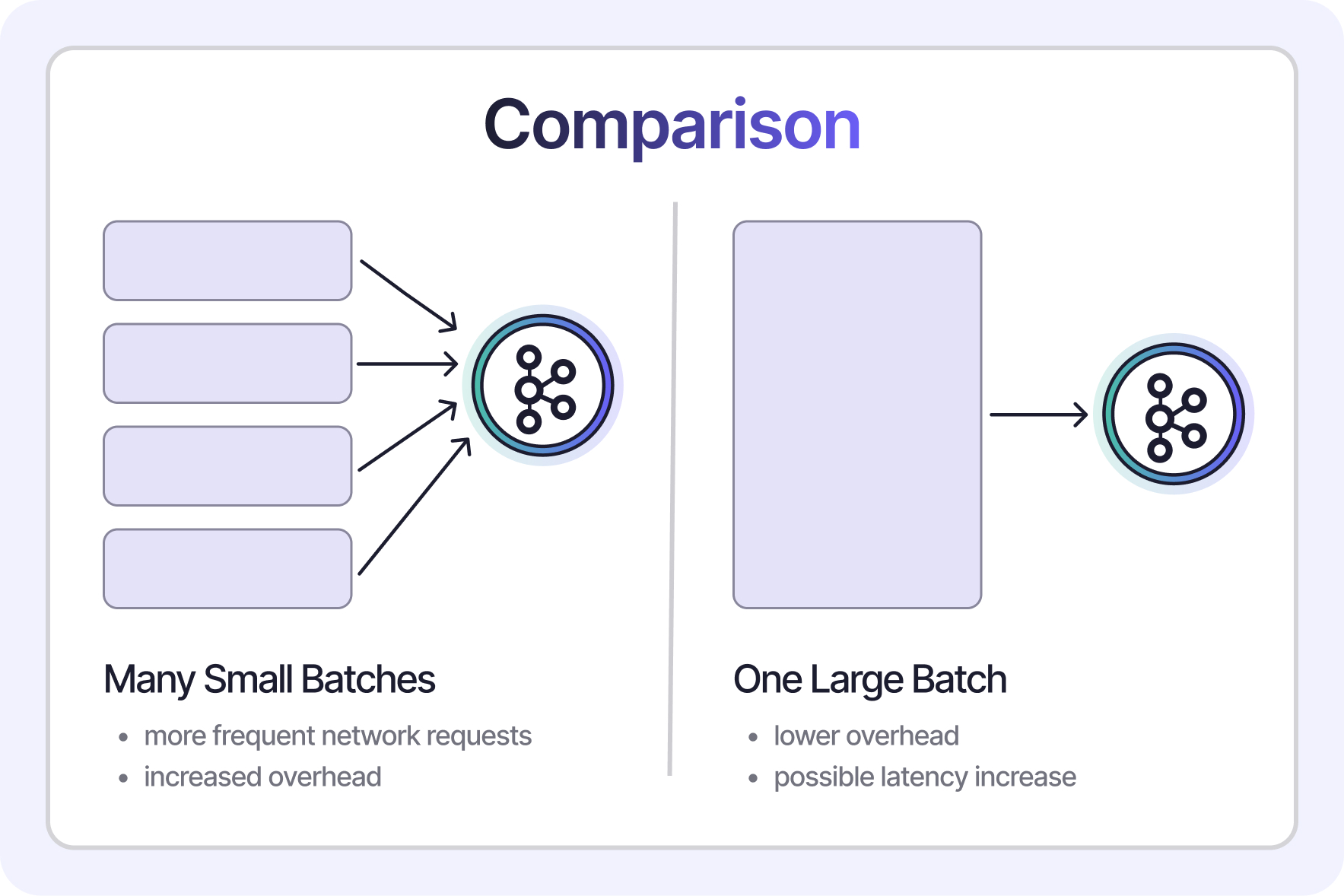
Kafka batch size determines how many records are grouped together before being sent to the broker. Choosing the optimal Kafka batch size has a direct impact on both system performance and your cloud bill.
Here’s why it matters:
- Larger batches = lower overhead per message, reducing total data transferred
- Smaller batches = higher frequency of network and I/O calls, which increases cloud costs
On platforms like Confluent Cloud, where pricing is based on ingress and egress, inefficient batching can result in unnecessary overages. Knowing how to set Kafka producer batch size effectively is essential for both technical and financial performance.
The Tradeoffs of Tuning Kafka Batch Size
Adjusting batch size isn’t as simple as picking a higher value. When tuning 1 vs 2 piece toilet—wait, scratch that—when tuning batch size, there are meaningful tradeoffs:
Larger batches:
- Lower overhead and better throughput
- Can increase memory usage
- May introduce latency if the batch isn’t filled quickly
- Must be balanced with linger.ms and compression
Smaller batches:
- Slightly reduce latency
- Increase API call frequency and data volume
- Can inflate costs due to inefficient transmission
The right Kafka producer batch size depends on your specific use case, SLAs, and workload characteristics.
Why Engineering Teams Struggle to Optimize Batch Size
Even experienced teams struggle with finding the best Kafka batch size. Common blockers include:
- Metrics are scattered across tools, offering no clear picture
- Producer and consumer patterns shift over time
- Safe testing environments require time and resources
- Manual tuning is time-consuming and error-prone
It’s not that engineers don’t care—it’s that optimizing something like the right Kafka batch size requires consistent visibility, experimentation, and time most teams don’t have.
How to Set Kafka Consumer Batch Size
Many teams focus on producers, but how to set Kafka consumer batch size matters just as much.
The right Kafka consumer batch size affects:
- Consumer lag
- Processing time per poll
- Memory footprint
- End-to-end latency
You can adjust this using the max.poll.records setting:
- For high-throughput use cases, increase the value to reduce polling frequency.
- For low-latency processing, keep batch size smaller to reduce per-poll delay.
Balancing batch size with fetch.min.bytes and fetch.max.bytes also helps optimize consumer behavior.
Strategies to Optimize Kafka Batch Size Without the Headache
Here’s how to improve batch size utilization safely:
- Monitor current batch size usage
Use Confluent’s built-in metrics to assess average and max batch sizes. This helps identify underutilized producers. - Tune batch.size with linger.ms
Larger batch.size often needs higher linger.ms values to fill effectively. Adjust them together and track results. - Enable compression
Using snappy or zstd can reduce network usage and pair well with larger batches. - Test in staging
Simulate real workloads before applying new settings in production. This lowers risk and helps you find the optimal Kafka batch size. - Use intelligent automation
Tooling like Superstream can monitor and dynamically tune configurations based on live traffic and load changes.
These are not just Kafka batch size best practices—they’re time-savers for modern engineering teams.
Apache Kafka Batch Size Calculator
Superstream created a simple, free-to-use Kafka batch size calculator that helps developers quickly determine the best configuration for:
batch.sizelinger.ms- Compression and memory thresholds
This tool doesn’t just suggest the right Kafka producer batch size—it gives you a complete profile for optimizing Kafka write performance based on your workload.
If you're unsure how to optimize Kafka batch size or just want a quick starting point, the Superstream Batch Size Calculator is a practical way to test different values and improve efficiency in seconds.
How Superstream Helps Teams Set the Right Kafka Batch Size Automatically
Getting the right Kafka batch size isn’t easy—but Superstream makes it automatic.
Instead of spending hours manually tuning configurations or risking production stability, Superstream’s no-code solution continuously monitors and optimizes both Kafka clusters and clients. It improves reliability, reduces cloud waste, and helps teams consistently apply Kafka batch size best practices without lifting a finger.
Here’s how Superstream simplifies how to set Kafka producer batch size and beyond:
- Auto-Optimize Clients Per Workload
SuperClient tunes batch.size, linger.ms, compression, and other producer configs dynamically—based on real-time workload behavior. No static config files. No guesswork. - Reduce Data Transfer & Compute Costs
Automatically applies the most efficient compression and batching strategy per client, cutting Kafka data transfer and compute usage by up to 60%. - Full Visibility & Metrics
Instantly access observability into how your batch settings affect throughput, latency, and network efficiency—without writing custom scripts. - Eliminate Waste with SuperCluster
Clean up zombie topics, idle consumers, and unused partitions—so your Kafka setup stays lean, efficient, and aligned with your policies. - Fast Setup, No Code Changes
Connect your cluster in minutes using a local agent and Superstream Console—no proxy, no code modifications. Get actionable insights immediately.
For teams looking to safely and automatically set the right Kafka consumer batch size, producer configuration, or cluster tuning, Superstream can be a game-changer. Start free and explore your own cluster with SuperStream.
.jpg)

.webp)


